Les réseaux de neurones récurents - rNN
Explicaitons simples et approfondies avec les maths

By Paul Claret
10 minutes read - 05/12/24
Nous avons vu deux types de réseaux de neurones pour le moment: ANN et CNN. Comme vu précedement, ils ont tous les deux leurs avantages et défauts. Nous n'avons pas encore d'architectures générale résolvant tout les problèmes.
Un problème que résoudent les RNN est la continuité de la donnée. C'est à dire que si nous prennons un CNN, nous pouvons analyser des images et detecter des objets... mais un CNN classique ne comprend pas les vidéos. Au final, une vidéo n'est qu'une suite d'image. Mais un CNN seul ne peut pas comprendre le lien entre chaque image.
Mais cela aussi pour tout type de données. Un ANN comme nous l'avons vu précédement, peux nous sortir des prédictions, mais il n'y a aucune notion de séquence ou temporalité. C'est là que les RNN entrent en jeux.
Quels sont les utilisations des RNN ?
Jusqu'à maintenant les RNN ont été souvent utilisé sur des projets demandant l'analyse de séquence de données. Soit:
Reconnaissance vocale
Audio, génération de musique...
Traduction
Prédiction du prix des actions
...
Bien que très peu utlilisé aujourd'hui sous leurs formes simple puisqu'ils comportent des défauts (vanishing gradient article), ils apportent un concept nouveau qui est utilisé dans beaucoup d'architecture nouvelles comme les transformers, l'attention...
Il est donc essentiel que vous sachiez comment ils fonctionnent avant de juste lire les nouvelles architectures, LSTM, GRU qui les remplacent.
Le principe
Jusqu'à maintenant, nous fournissions des données au model à un temps t. Un IRM d'un patient, une photo de chat... Et le model nous donnait une sortie simple. Les RNN eux demandent une séquence en entrée et ils peuvent avoir une ou plusieur sortie en fonction de ce que l'on veut faire.
Ils présente aussi de nombreux avantages aux model traditionels:
| Avantage | Inconvéniant |
|---|---|
| - L'entrée peut être de la longueure que l'on veut (elle n'est pas fixé) - La taille du model n'augmente pas avec une augmentation de l'entrée - Traitement des données séquentielles - Partage des poids au court du temps (réduction de la taille mémoire prise par le model) |
- Lent à calculer - Difficulté d'accès à des données très anciennes |
Les types de RNN
| Type of RNN | Illustration | Example |
| One-to-one |
 |
ANN classique (aucune différence) |
| One-to-many |
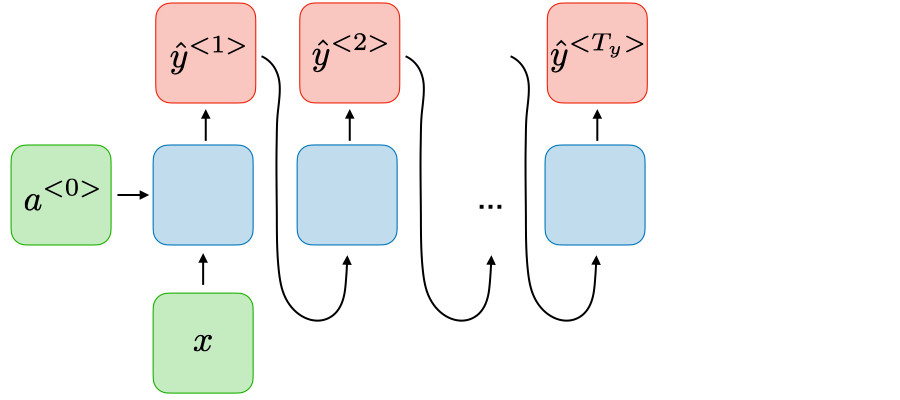 |
gnération de musique |
| Many-to-one |
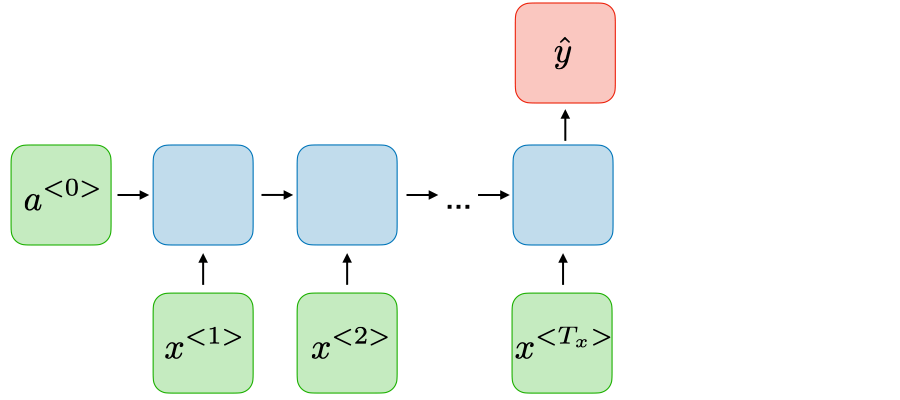 |
Classification de sentiments |
| Many-to-many |
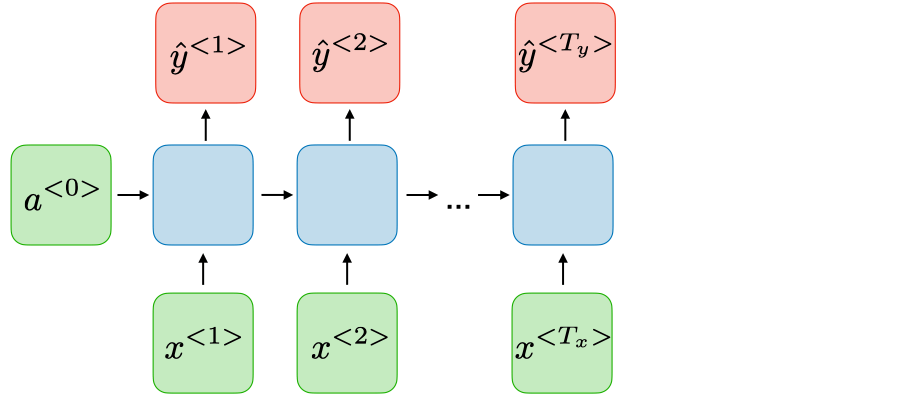 |
Name entity recognition |
| Many-to-many |
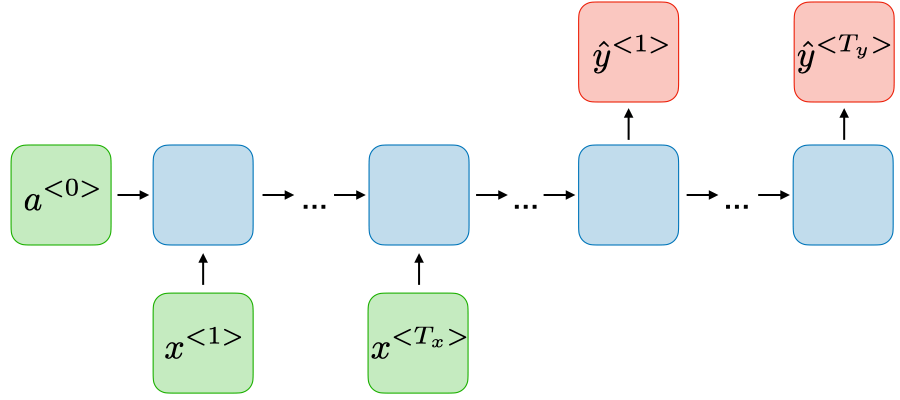 |
Traduction |
source: CS 230 - Recurrent Neural Networks Cheatsheet
L'interieur d'un RNN
Donc en quoi un RNN diffère-t-il d'un ANN ou CNN ? Un RNN est effectivement un ANN auquel on a rajouté une matrice de poids qui vient du réseaux de neurones précedent.
On représente souvent les RNN à la verticale avec l'entrée X en bas, la sortie Y en haut et une bulle avec une flèche poitant sortant et dirigé vers soit-même h pour *"hidden"*.
Ce h rend souvent les gens confu puisqu'ils se disent qu'il ne s'agit que d'une matrice du style et donc que c'est un simple ANN a une seul couche avec une flèche étrange pour faire joli.
Mais pas du tout.
Un RNN est en réalité un réseaux de neurone classique auquel on va faire 2 opérations supplémentaires. Le schéma ci dessous aide à voir de quoi sont fait les différents composants du RNN.

Vous me direz donc en quoi sont-il spécial ?
D'abord, commençont par déplier l'architecture. Car ce schéma présente le RNN sous sa forme pliée.
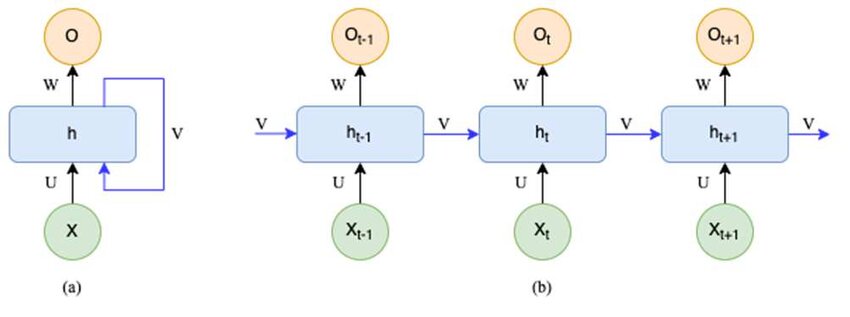
Sur ce schéma, vous pouvez faire à gauche la forme plié et à droite déplié.
Vous remarquerez qu'il s'agit de plusieurs ANN connectés les uns aux autres. Pour être plus précis, ce sont des ANN qui prennent une entrée supplémentaire vennant du model précedent et ont une sortie intermediaire connecté au ANN suivant. Pour le premier ANN, il s'agit d'un vecteur d'initialisation aléatoire qui sera adapté lors de la backpropagation. Mais pour les éléments suivants, il s'agit d'un calcul à partir de l'entrée précédente. On va le voir plus en détail.
Voici une vision interne d'un ANN pour le RNN:
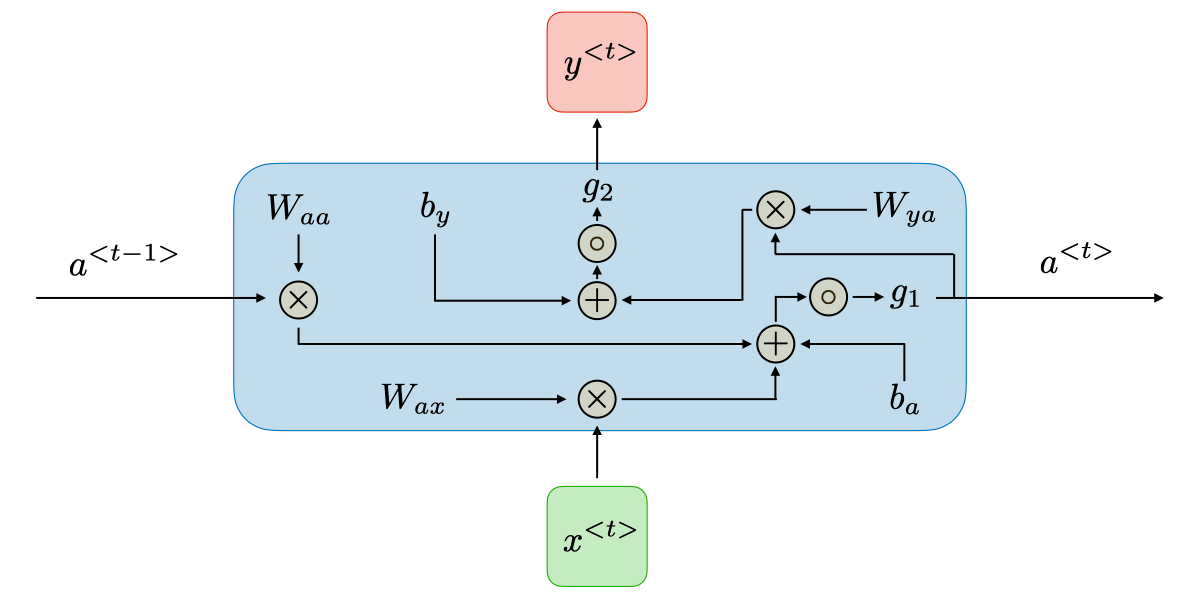
Ca peut paraitre intimidant au premier coup d'oeil mais c'est très simple. Commençons par définir les termes:
est la ième entrée. Dans une phrase cela peut être le ième mot...
est le vecteur d'initialisation caché
est une matrice de poids classique qui sera multilié par le vecteur d'initialisation
est une matrice de poids classique qui sera multiplié avec l'entrée
est une matrice contenant les bias (tout comme un ANN classique)
fonction d'activation (au choix. souvent tanh, sigmoid, relu...)
Avant de passer au termes suivants, je voudrai prendre 2 secondes pour résumer la première partie du calcul d'un RNN.
Ici nous avons notre vecteur d'initialisation venant du RNN précedent (si premier RNN = random). On le multiplie avec une matrice de poids . On fait de même avec notre entrée et et on additione les poids à ce dernier calcul. On y additionne ensuite le résultat du produit du vecteur d'initialisation et de la matrice de poids , et on passe le tout dans la fonction d'activation . Ce terme en sortie est le vecteur d'initialisation pour le RNN suivant et le prochain calcul du RNN.
Sous forme d'équation cela donne ceci:
Il nous manque encore la prédiction du RNN ici. C'est la seconde partie du calcul. Voici donc les termes suivants:
un matrice de poids pour le calcul de la sortie
un matrice de poids pour la calcul de la sortie
une deuxième fonction d'activation
Si vous avez compris mon article sur les ANN il n'y a rien de magique ici. C'est une simple multiplication et additon de matrice et un passage dans la fonction d'activation. Donc le calcul est le suivant:
Et la backpropagation ?
Souvent la bête noire quand on apprend l'IA et le deep learning, parceque c'est souvent survolé et vu comme une boite noire de "on calcul le gradient et laisse l'ordinateur faire"... Mais c'est essentiel de comprendre le détail pour pouvoir ensuite débugger.
Le problème du vanishing/exploding gradient
Le problème aussi avec les RNN, c'est que pour le calcul du gradient, celui-ci est souvent soumis à 2 pronlèmes. Le vanishing gradient et exploding gradient. 
Dans un cas, le gradient devient tellement grand que le model fini par apprendre n'importe comment et faire des prédictions presques aléatoires. Dans l'autre, le gradient devient tellement petit qu'il fini par ne plus apprendre et le model ne s'améliore plus.
Cela vient du fait que le gradient se propage du dernier "RNN" au premier "RNN". Donc à force de passer de RNN en RNN, celui ci devient soit énorme soit minuscule.
Des RNNs améliorés: LSTM et GRU
La raison pour laquelle on n'utilise plus des RNN simples est justement à cause de ces histoires de gradient. Pour cela on a trouvé deux solutions principales. Les LSTM (Long Short Term memory) et les GRU (Gated Recurrent Unit).
Ces deux architectures sont donc plus utilisées aujourd'hui et je vais vous les présenter dans les articles suivants :)
Je voudrai aussi vous présenter une autre architecture intéréssante: les Deep RNN. Ce sont des RNN empilé les uns sur les autres comme sur l'image ci dessous:

Au lieu de prendre la sortie de pour , on le refait passer dans un RNN puis un autre... autant de RNN que l'on veut. Je ne présenterai pas cette architecture dans le détail donc je ne fais que la mentionner ici pour que vous en soyez informé et puissiez faire vos propres recherches de votre côté. Ce n'est pas une architecture commune mais elle est sympa à connaitre. Ils sont particulièrement utile pour comprendre la complexité dans de très longues séquences de données.
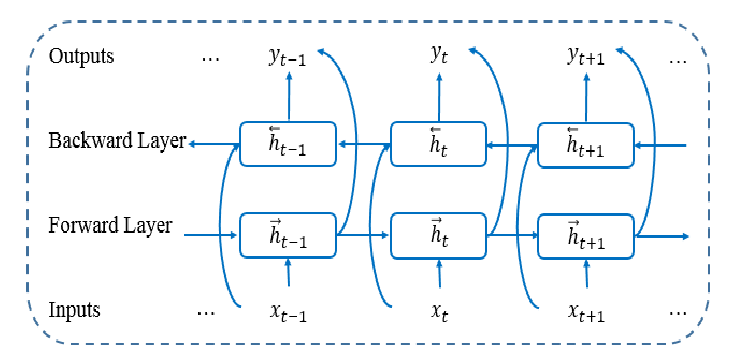
Et puis encore un petit: les RNN bidirectionels (idem je vous laisse avec une iamge et laisse faire vos recherches si vous voulez vous y interesser.):
Vous voulez apprendre l'IA en autonomie ?
Si vous êtes nouveau sur mon site, je vous invite à aller voir ma page sur Roadmap IA qui regroupe tous mes articles dans l'ordre pour vous facilitez l'apprentissage.