Les réseaux de neurones convolutionels - CNN
Explicaitons simples puis approfondies avec les maths

By Paul Claret
10 minutes read - 03/12/24
Il existes différents réseaux de neurones pour différentes applications. Aussi simple que cela. Certains fonctionnement mieux avec des données textuelles, audios... Aujourd'hui je vous parle des réseaux de neurones qui fonctionnent le mieux sur les images. Les Convulutional Neural Network ou CNN pour la faire court.
Le principe
Pour nous humain, il est facile de reconnaitre un chat avec une image. Si je vous donnes les images ci dessous, quand bien même elles sont différentes, vous voyez toujours le chat, bien qu'il soit d'un angle différent, une limuière différente et parfois partiellement visible.



Ce n'est pas aussi simple pour un ordinateur. Si je vous affiche la représentation de ces iamges comme un ordinateur les voit, voilà à quoi ça ressemble:

Alors, il est où le chat ?
Pour qu'un ordinateur puisse reconnaitre des objets dans des images, nous n'allons pas utiliser une réseaux de neurone classique comme nous l'avons vu précédement mais avec des filtres qui analyzent des parties de l'image partie après partie.
Le réseaux
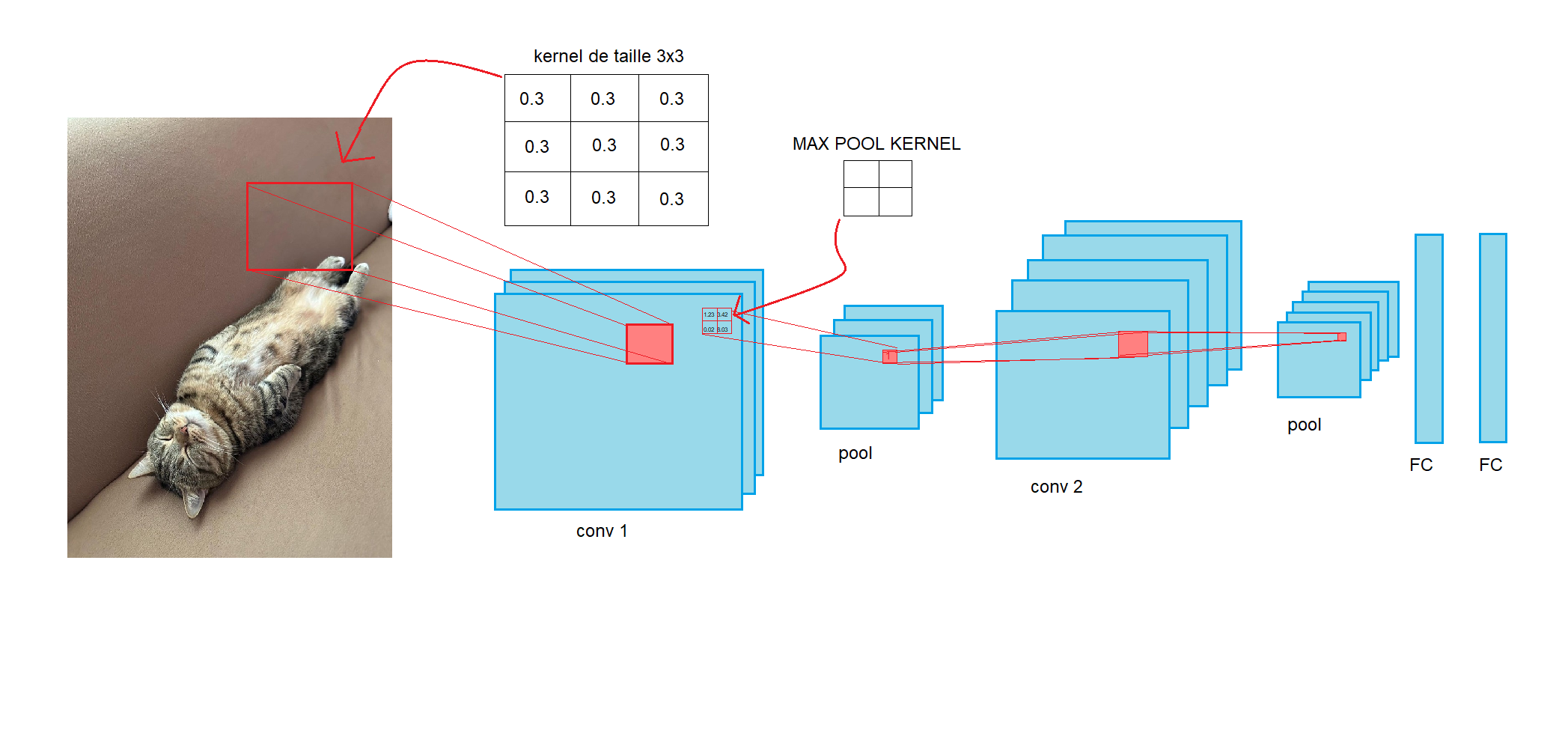
L'image ci dessus résume entièrement le principe d'un CNN. Nous avons notre image de chat en entrée et on va appliquer un filtre que l'on appèle kernel. Ce kernel (présent au dessus de notre image) contient des poids (tout comme pour les réseaux de neurones artificiel simples). Ces poids sont ensuite multiplié aux pixels de notre image et nous donne une seule valeurs en sortie (vous verrezplus loin l'application manuelle comment la multiplication marche).
Après avoir passé notre kernel sur toute notre iamge, nous obtenons alors une nouvelle image que l'on appel conv (ce sont "les sorties des neurones d'un cnn"). Vous voyez, que l'on a 3 layers de conv 1.
Petit rappel sur ce que sont les images
Les images sont des matrice qui contiennent des valeurs de pixel rouge, vert et bleu. Chaque pixel présent sur votre écran contient 3 LED: une rouge, une verte et une bleu.

A l'oeil nu, ces leds ne sont pas distinguable mais physiquement si vous vous rappelez de votre cours de physique au lycée, vous savez qu'en additionant ces trois couleurs, vous pouvez obtenir n'importe quel couleur sous l'arc en ciel. Si vous voulez avoir un pixel rouge, il faut allumer seulement la led rouge et éteindre les deux autres etc. Vous savez probablement déjà tout ça.
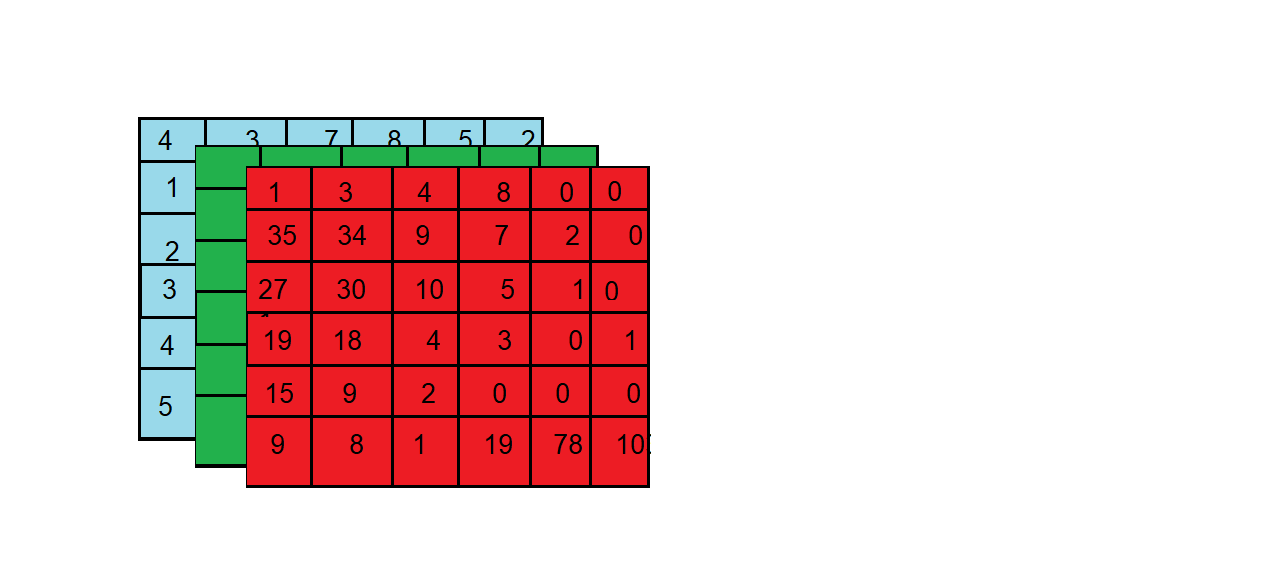
Donc une image est une carte composé de 3 couches qui indique à quels points les rouges doivent être activées, à quel point les bleus doivent l'être... Cela nous donne donc 3 matrices qui forment une image. Voici un example:
Le nombre de couches de convolution
Le nombre de couche de convolution que vous allez sortir de votre image est comlétement arbitraire et à vous de le decider.
Vous aller appliquer un kernel de taille YxYxZ avec Z la profondeur de l'image. regardez l'image ci dessous:
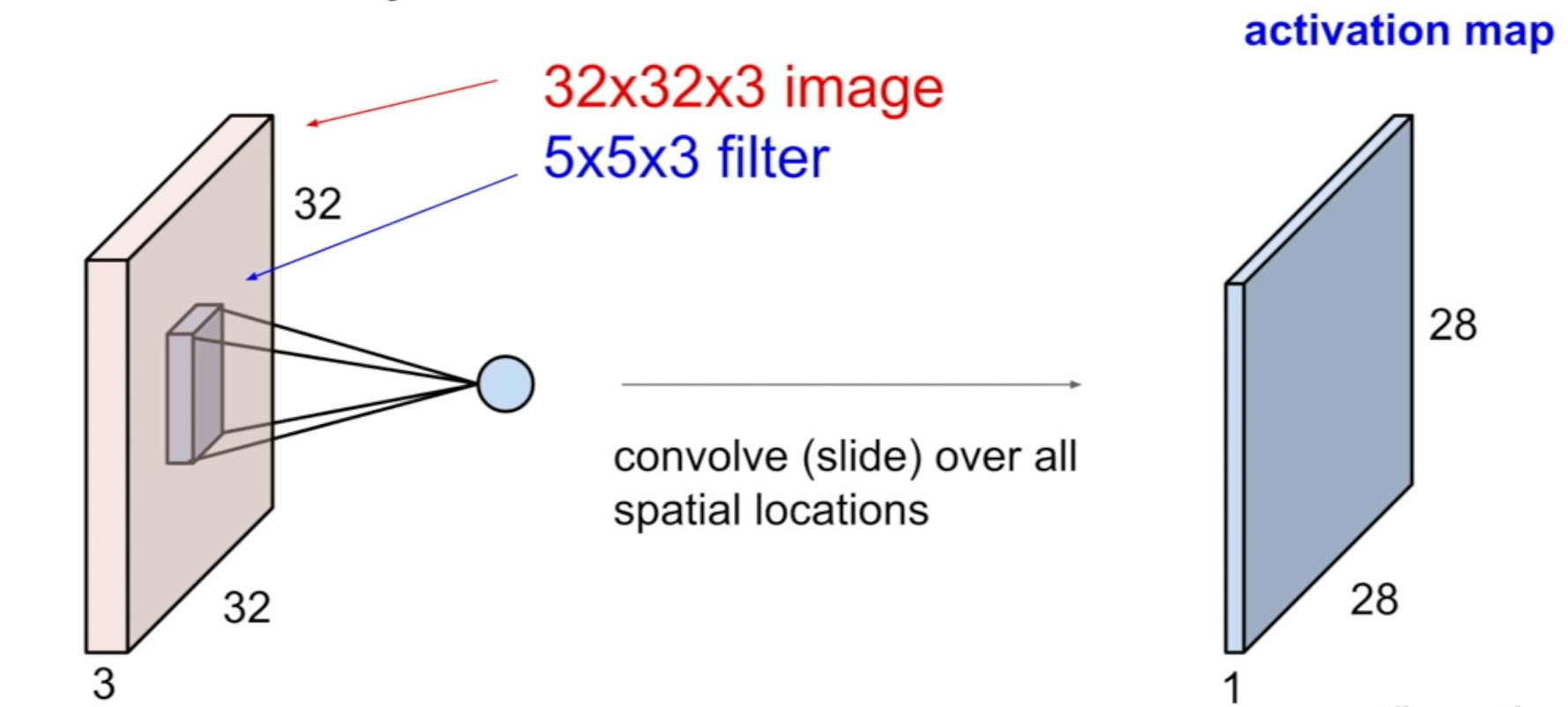
En entrée, nous avons une aimge de taille 32x32 (avec la profondeur de 3 puisque c'est une iamge RGB comme expliqué précedement). Nous passons notre filtre de taille 5x5 et profondeur 3 sur toute notre image pour sortir une carte d'activation. C'est ce que j'ai appelé les conv 1 et conv 2.
Pour avoir 3 couches de convolution en sortie il suffit de passer 3 filtres différents sur notre image.
En règle générale, plus vous avez un grand nombre de couche en sortie plus votre model va comprendre différentes particularités de l'image mais plus il va être gros et consomer des ressources.
Attention ! Les CNN peuvent vite devenir très gros et consomer toutes vos ressources ! Soyez méticuleux dans le choix de la taille de vos kernel, images, et nombre de layer. En règle générale, c'est bien de commencer par des tailles petites comme 3x3 et mettre entre 3 à 12 couches max. J'ai écris un autre article sur le choix des tailles des matrices... et les calculs de ressources nécéssaire ici: Bien définir l'architecture de votre réseaux de neurones CNN-RNN-etc
Le pooling
Après avoir obtenu nos couche de convolution, nous allons maintenant appliquer ce que l'on appèle le pooling. C'est la même chose que pour les fonctions d'activation mais pour les images. plutôt que de garder une image très grande à chaque couche, nous allons la simplifier avec une fonction qui va prendre les pixels les plus importants et se débarasser des autres.
Généralement, il y a deux fonctions utilisés: maxpool et avgpool.
Le maxpool, comme son nom l'indique, prend la valeur maximale parmis une partie de l'image et jette les autres. Le avgpool ou average pool quant à lui, prend les moyenne de chaque pixel et garde cette valeur. Vous choisissez celle que vous voulez.
Voici une image résumant très bien le principe des deux fonctions:

Comme vous pouvez le voir, le kernel de ce pooling layer, est de taille 2x2. On commence en haut à gauche et regarde la matrice
On prend la plus grande valeur dans cette matrice et on la met en haut à gauche de la matrice de pooling. on déplace ensuite le kernel sur les pixels suivants et on prend la plus grande valeur:
On continu jusqu'à ce que l'on ai parcouru toute la matrice de convolution.
Je vous laisse faire les calculs si vous souhaitez experimenter avec le average pool.
Et on recommence !
Une chose que j'ai oublié de mentioner est que les pooling layer sont seulement de taille profondeur 1. C'est à dire qu'il y a autant de pooling layer que de couche de convolution en entrée. Si vous regardez le schéma du début, vous remarquerez que chaque pool a autant de couche que les convolution précédentes.
Maintenant que l'on a nos couche de pooling calculées, on réapplique une couche de convolution et encore une de pooling. On met autant de couche de convolution et pooling que l'on veut. On peut même mettre plusieurs couche de convolution les unes après les autres sans pooling entre. Vous être libre de créer l'architecture que vous voulez. Pour vous donner une idée d'une architecture faite par un expert en IA. Je vous présente le réseaux AlexNet. Créé par les meilleurs chercheurs et ingénieurs en IA de nos jours: Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton

Architecture AlexNet
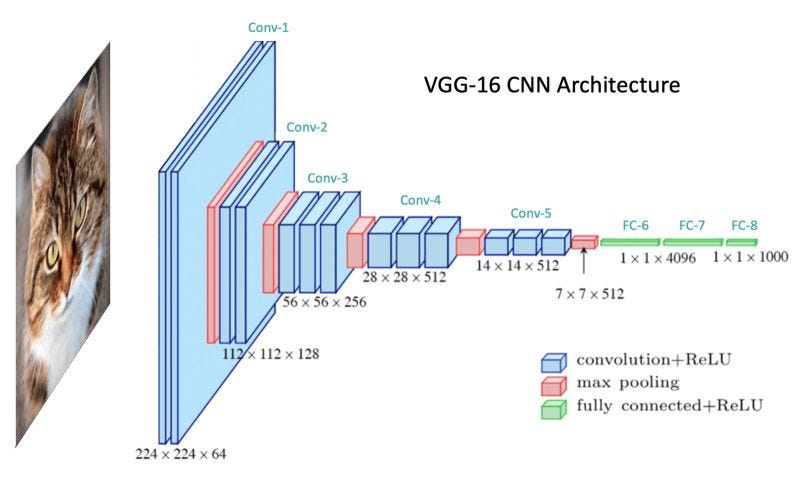
En bonus, voici l'architecture VGG-16:
La couche de convolution dans le détail
Si vous avez bien regardé l'architecture AlexNet, vous avez remarqué qu'il a des mots que l'on a pas encore abordé: stride, pad. 🤔
Pour vous l'expliquer, j'ai besoins de plonger dans le détail du calcul de la couche de convolution.
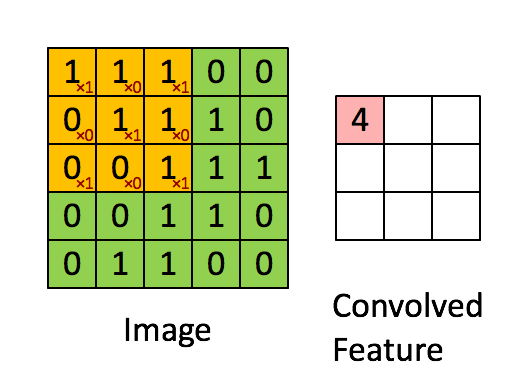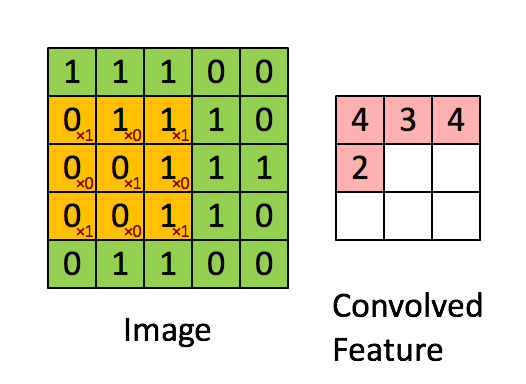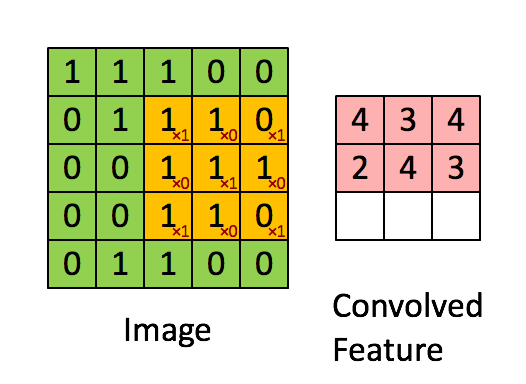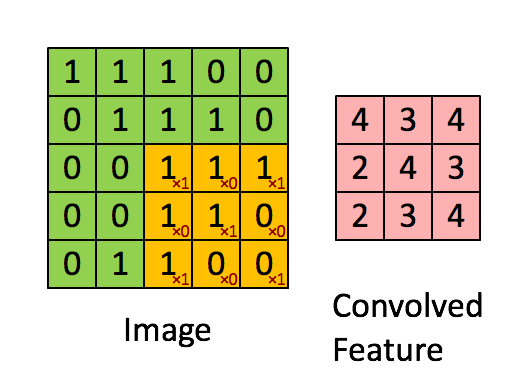
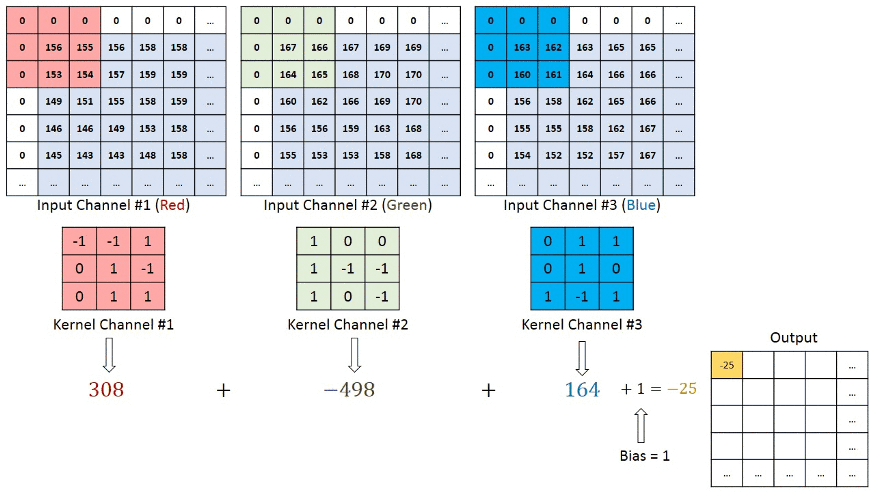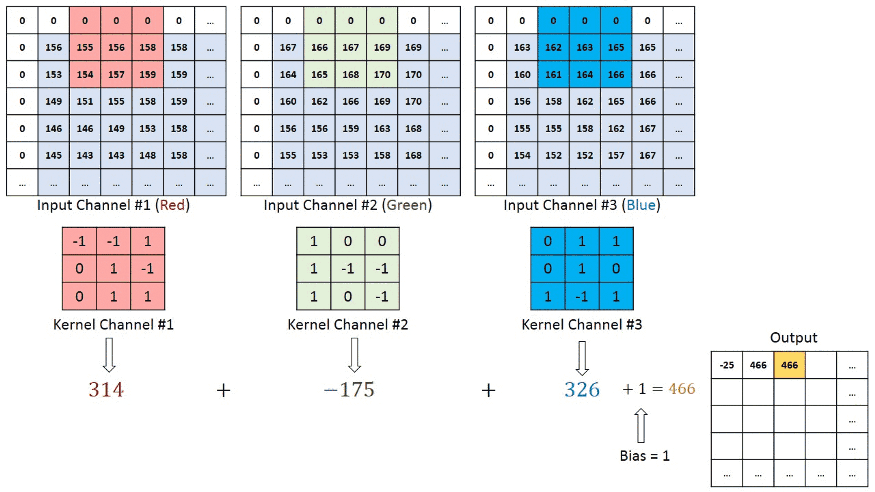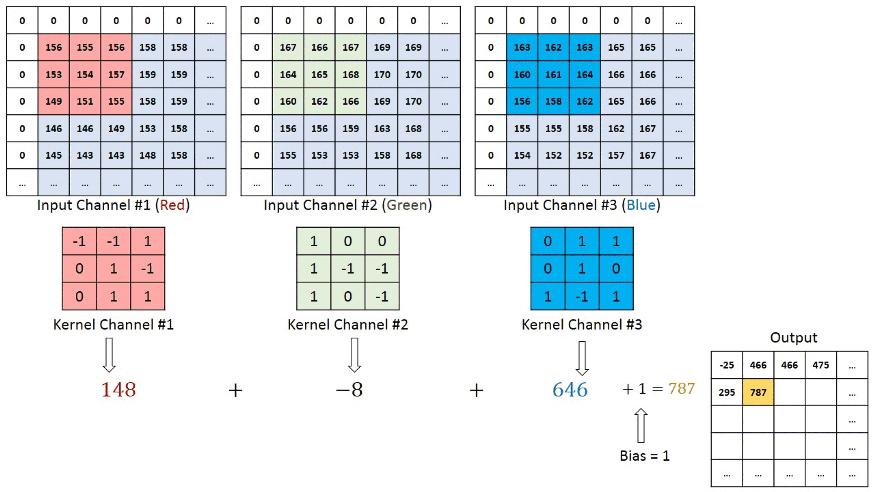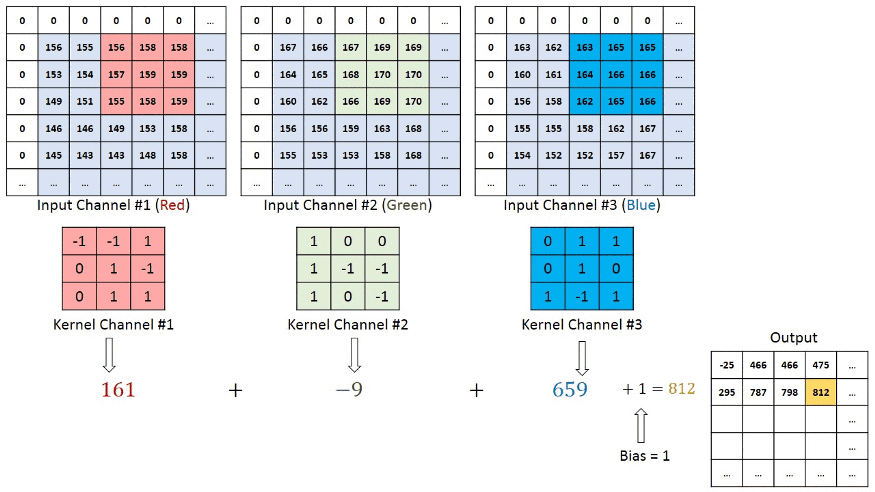
Je vous ai expliqué que l'on passait un kernel sur notre image et en sortait un nombre sans plus de détails. Je trouve personellement qu'un gif vaut mieux que 1000 mots pour l'expliquer donc voici le calcul de la convolution:

Ici on a simplifié le calcul sur une couche en mettant que des 0 et 1. On commence comme pour le pooling en haut à gauche de notre image (input data). On le multiplie par notre kernel et additionne le résultat. Attention, ce n'est pas une multiplication de matrice comme en maths:
Ici on prend chaque élément de matrice et les multiplie un a un. Càd que l'on commence en haut à gauche dans chaque matrice (1 et 1) et on les mutltiplie . On continue pour l'élément suivant (ligne 1 colonne 2: 1 et 0). On les multiplies: . On continu pour toute la matrice et on fini par additioner tous les élements de la matrice entre eux.
Dans notre matrice le résultat vaut 4. Si vous regardez le résultat en haut à gauche de la matrice convoluted feature, on a un 4. L'exemple continue ensuite en prennant la partie du haute du milieux et ensuite la partie haute droite...
On continue jusqu'à ce que la matrice soit pleine.
Le stride
Le stride est le pas entre chaque calcul de matrice. Dans tous les example précents, nous avons balayé la matrice avec notre kernel de pixel en pixel soit un stride de 1. Si nous sautons de 2 pixel en 2 pixels, notre stride est de 2.
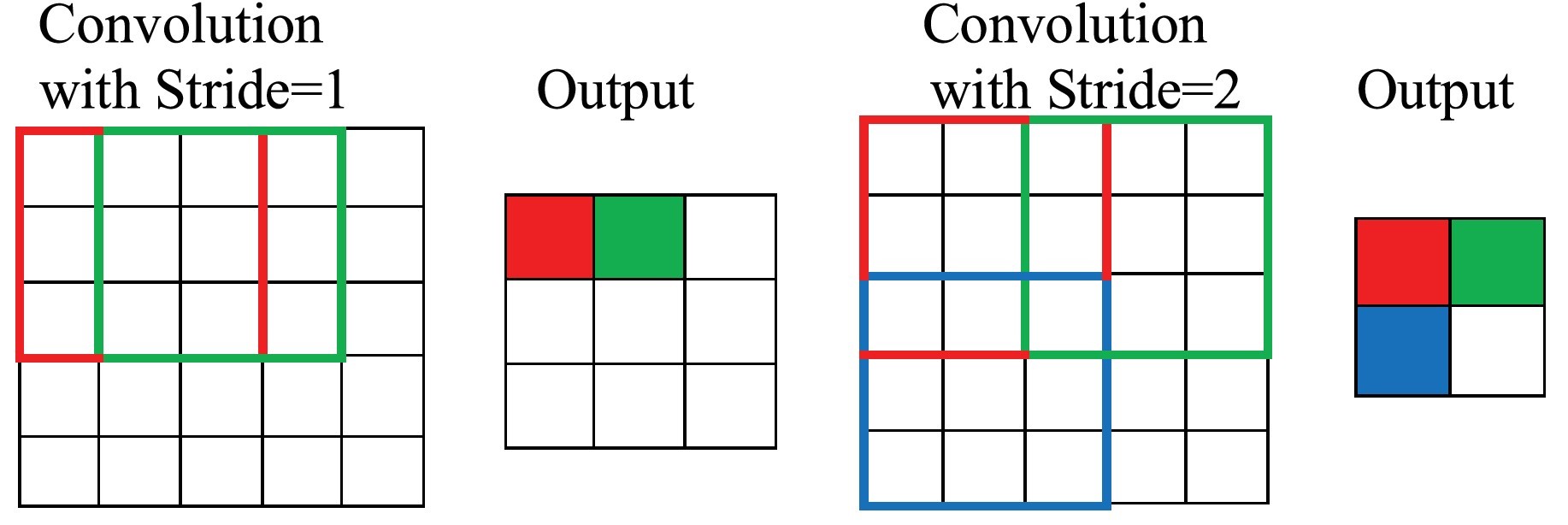
Sur l'image ci dessus, nous avons un kernel 3x3 et faison le même calcul que précédement à l'exception que comme vous pouvez le voir avec les couleurs, notre deuxième calcul est décalé de 2 pixels.
Vous remarquez aussi que cela à une influence sur la taille de la sortie. Donc que se passe-t-il si l'on dépasse ntore input/on prend une stride trop grande ?
C'est là que le pad à son importance.
Le padding
Pour fixer la règle, pour que votre taille de kernel et stride soient bon, il faut que la taill de l'entrée - la taille de votre kernel divisé par votre stride soit un nombre entier. Voici la formule
D'ailleur, la taille de la sortie sera:
Alors comment faire si l'on veut une taille de kernel qui ne va pas avec le stride ? On rajotue des 0 en brodure de notre input.
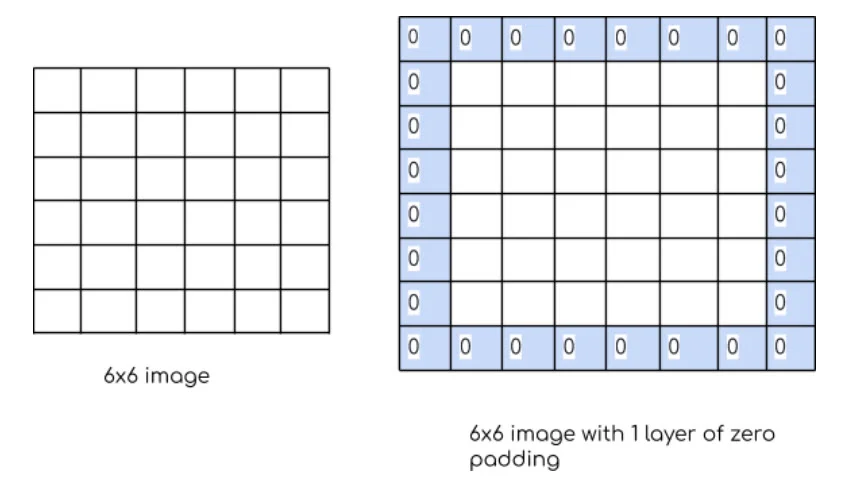
Combien de couche 0 faut-il ajouter ? Autant que nécéssaire pour que votre kernel et stride fonctionnenet avec votre image. Si vous vous voyez ajouter plus de 3 layer de padding, vous ferez mieux de changer de stride et kernel par contre.
Le tout en un GIF !
Pifou, j'ai rédigé tout cet article d'un coup et ça commence à être long. Mais au moins, vous avez vu tout ce qu'il y a à savoir sur les CNN pour déjà créer votre propre architectures !
Alors voilà un gif qui résume tout:
Pour ce qui est la backpropagation, le principe est le même, on actualise les poids des kernel et des matrices de bias (oui il y en a. juste que c'est qu'une simple addition donc je l'ai pas mentioné).
Pour finir: les couches fully connected
Sur l'image des architectures, il y plusieurs couches FC connectés après toutes nos couches de convolution et pooling. Ces couches FC sont des réseaux de neurones artificiels simples comme vu dans les articles précédents.
Ces couches servent souvent à prédire un label... tel que chiens ou chat. (La partie prédiciton de notre model quoi).
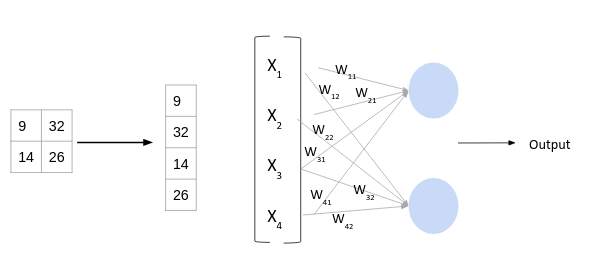
Cependant, pour faire passer les données de dimensions 2D (pour les images) aux dimensions de l'ANN, il faut le faire passer dans une dimension 1. C'est le role du flatten layer. Il prend une matrice et la transforme en une ligne comme ceci:
Conclusion
Vous vous demandez surement est-ce que tout ça est pas bullshit ? Comment juste des matrices peuvent reconnaitre des animaux. Et bah voici un petit apperçu dans un model qui a été entrainé:

Vous voyez ici des cartes d'activation pour les images ) côté. Ces cartes d'activation (bien que peu visible avec la qualité de l'image), s'activent sur des zones tel que les bords, et diagonales...
Tout celà permet au réseaux de neurones de reconnaitre des images. Si c'est pas fou.
Je vous invite à regarder le tuto suivant ou je vais construire avec vous non pas 1 mais 2 réseaux de neurone artificiel pour prédire des chiffres écrit à la main et les cancers du cerveau. Oui oui on va prédire si des gens ont des tumeurs aux cerveaux avec une IA !
Vous voulez apprendre l'IA en autonomie ?
Si vous êtes nouveau sur mon site, je vous invite à aller voir ma page sur Roadmap IA qui regroupe tous mes articles dans l'ordre pour vous facilitez l'apprentissage.